
本文于 2025年8月17日 9:17 更新,注意查看最新内容
阿里小号前段时间发布公告,说要全面下线阿里小号业务(目前暂停),于是着手准备换绑事宜,由于使用快接近十年,注册的平台数不胜数,手动统计起来极其麻烦,于是查找了相关方案,这里记录相关核心信息,以备日后查阅。
阿里小号的短信主要有两种方式接收,一种是直接转发至本机,另一种是在阿里小号APP内查看,本文两种接收方式的统计均会有所介绍,请放心浏览。
阿里小号APP内短信的导出:
原理:利用 adb shell uiautomator dump 循环滚动读取短信界面数据,模拟人工导出短信内容。
1、导出
# adb连接手机 adb devices # 打开阿里小号 App 的短信界面,并保持在首屏 python export_sms.py # 脚本会自动循环滚动并抓取短信内容,导出到 conversation_list.csv
import os
import re
import subprocess
import time
import xml.etree.ElementTree as ET
def run_adb_command(command):
"""执行ADB命令并返回输出"""
result = subprocess.run(command, shell=True, capture_output=True, text=True)
if result.returncode != 0:
return None
return result.stdout.strip()
def pull_ui_dump(file_path):
"""拉取UI Dump文件,确保文件生成成功"""
device_path = f"/sdcard/{os.path.basename(file_path)}"
# 生成UI转储并等待文件创建
run_adb_command(f"adb shell uiautomator dump {device_path}")
time.sleep(1.2) # 延长等待时间,确保文件生成
run_adb_command(f"adb pull {device_path} {file_path}")
run_adb_command(f"adb shell rm {device_path}")
return os.path.exists(file_path)
def extract_list_items(xml_file):
"""提取列表项,确保元素识别稳定"""
items = []
try:
tree = ET.parse(xml_file)
root = tree.getroot()
# 元素标识常量(与UI Dump匹配)
LIST_CONTAINER_ID = "com.alicom.smartdail:id/xiaohao_conversation_list"
NAME_ID = "com.alicom.smartdail:id/xiaohao_item_conversation_name"
TIME_ID = "com.alicom.smartdail:id/xiaohao_item_conversation_time"
CONTENT_ID = "com.alicom.smartdail:id/xiaohao_item_conversation_body"
# 查找列表容器
list_container = root.find(f".//node[@resource-id='{LIST_CONTAINER_ID}']")
if list_container is None:
return items
# 遍历所有可点击的列表项
for node in list_container.iter('node'):
if node.get('class') == 'android.widget.LinearLayout' and node.get('clickable') == 'true':
# 查找关键子元素
name_node = node.find(f".//node[@resource-id='{NAME_ID}']")
time_node = node.find(f".//node[@resource-id='{TIME_ID}']")
content_node = node.find(f".//node[@resource-id='{CONTENT_ID}']")
# 确保元素存在且有内容
if (name_node is not None and time_node is not None and content_node is not None and
name_node.get('text') and time_node.get('text') and content_node.get('text')):
items.append({
'name': name_node.get('text'),
'time': time_node.get('text'),
'content': content_node.get('text')
})
except Exception as e:
print(f"解析错误: {e}")
return items
def get_screen_size():
"""获取屏幕尺寸(缓存结果)"""
if not hasattr(get_screen_size, 'cached_size'):
output = run_adb_command("adb shell wm size")
if output:
size_match = re.search(r"(\d+)x(\d+)", output)
if size_match:
get_screen_size.cached_size = (int(size_match.group(1)), int(size_match.group(2)))
return get_screen_size.cached_size
get_screen_size.cached_size = (1080, 2210) # 默认值
return get_screen_size.cached_size
def scroll_down():
"""优化滚动逻辑,确保滚动距离足够"""
width, height = get_screen_size()
# 增加滚动距离(从屏幕2/3处滑到1/4处)
start_x, start_y = width//2, height*2//3
end_x, end_y = width//2, height//4
run_adb_command(f"adb shell input swipe {start_x} {start_y} {end_x} {end_y} 250") # 延长滑动时间
def main():
os.makedirs("temp_dumps", exist_ok=True)
all_items = []
prev_items = [] # 存储上一页完整内容,用于更准确的底部判断
page = 1
consecutive_same = 0 # 连续相同页数计数(避免误判)
max_consecutive = 2 # 连续2页相同才判断为底部
max_pages = 1000 # 增加最大页数限制
print("开始收集列表数据(完整模式)...")
while consecutive_same < max_consecutive and page <= max_pages:
dump_file = f"temp_dumps/page_{page}.xml"
if not pull_ui_dump(dump_file):
print(f"页面 {page} 获取失败,重试...")
page += 1
continue
current_items = extract_list_items(dump_file)
if not current_items:
print(f"页面 {page} 未找到数据,继续...")
page += 1
continue
# 计算新增数据量
seen_items = set((i['name'], i['time'], i['content']) for i in all_items)
new_count = 0
for item in current_items:
item_key = (item['name'], item['time'], item['content'])
if item_key not in seen_items:
seen_items.add(item_key)
all_items.append(item)
new_count += 1
# 判断是否与上一页内容相同(优化底部判断)
if prev_items and len(current_items) == len(prev_items):
# 比较所有项而非仅最后一项,避免误判
if all(current_items[i] == prev_items[i] for i in range(len(current_items))):
consecutive_same += 1
else:
consecutive_same = 0
else:
consecutive_same = 0
prev_items = current_items.copy()
print(f"页面 {page} 新增 {new_count} 项,总计 {len(all_items)} 项")
# 继续滚动
if consecutive_same < max_consecutive:
scroll_down()
page += 1
time.sleep(1.5) # 延长滚动后等待时间,确保内容加载
else:
print(f"连续 {max_consecutive} 页内容相同,判断为已到达底部")
# 导出结果
if all_items:
csv_file = "conversation_list.csv"
with open(csv_file, "w", encoding="utf-8") as f:
f.write("号码,时间,内容\n")
for item in all_items:
name = item['name'].replace('"', '""')
time_val = item['time'].replace('"', '""')
content = item['content'].replace('"', '""')
f.write(f'"{name}","{time_val}","{content}"\n')
print(f"\n完成! 共收集 {len(all_items)} 条记录")
print(f"结果已导出到: {csv_file}")
else:
print("未找到任何列表项")
# 清理临时文件
try:
for file in os.listdir("temp_dumps"):
os.remove(os.path.join("temp_dumps", file))
os.rmdir("temp_dumps")
except:
pass
if __name__ == "__main__":
main()
执行完上述代码之后,会在执行目录生成一个conversation_list.csv。
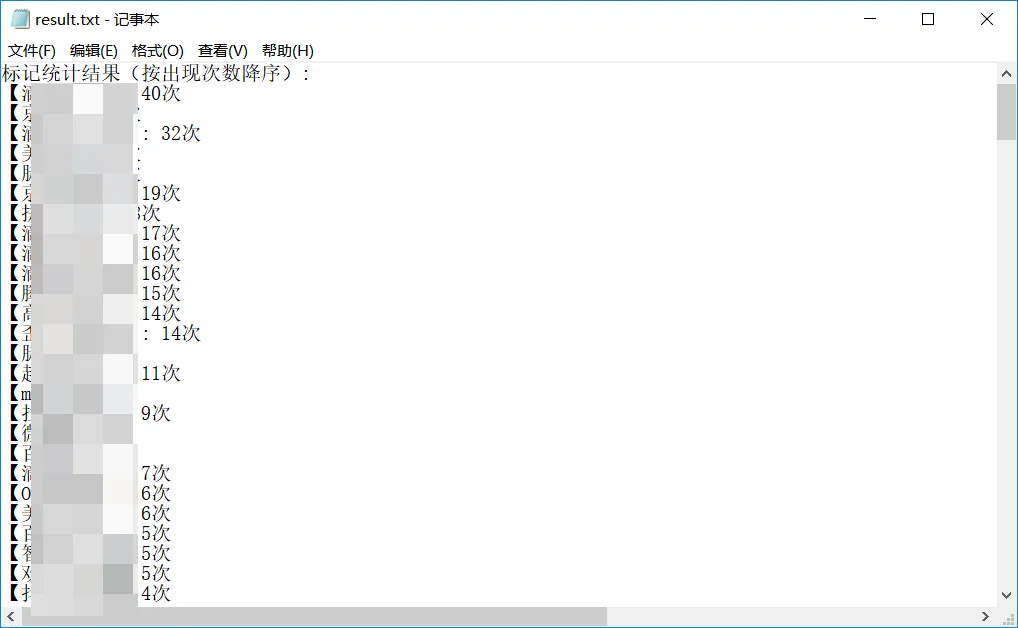
2、统计
# 修改脚本中的 input_file 指向你的短信导出文件 python stats_platforms.py
def process_file(input_path, output_path):
tag_counts = {} # 存储【xxx】标记及其出现次数
no_tag_lines = [] # 存储不包含标记的行内容
required_string = "" # 其他地方导出时可以填写小号号码以区分
with open(input_path, 'r', encoding='utf-8', errors='ignore') as file:
for line in file:
# 检查是否包含
if required_string and required_string not in line:
continue
# 查找第一个【xxx】标记
start_idx = line.find("【")
end_idx = line.find("】", start_idx + 1) if start_idx != -1 else -1
if start_idx != -1 and end_idx != -1:
# 提取第一个完整标记
tag = line[start_idx:end_idx + 1]
tag_counts[tag] = tag_counts.get(tag, 0) + 1
else:
# 记录不包含标记的行
no_tag_lines.append(line.strip())
# 按出现次数降序排序
sorted_tags = sorted(tag_counts.items(), key=lambda x: x[1], reverse=True)
# 将结果写入输出文件
with open(output_path, 'w', encoding='utf-8') as out_file:
# 写入标记统计结果
out_file.write("标记统计结果(按出现次数降序):\n")
for tag, count in sorted_tags:
out_file.write(f"{tag}: {count}次\n")
# 写入无标记行
out_file.write("\n不包含标记的行:\n")
for i, line in enumerate(no_tag_lines, 1):
out_file.write(f"{i}. {line}\n")
return sorted_tags, no_tag_lines
# 使用示例
if __name__ == "__main__":
input_file = "conversation_list.csv" # 输入文件路径
output_file = "result.txt" # 输出文件路径
tags, lines_without_tags = process_file(input_file, output_file)
print(f"处理完成!结果已保存到 {output_file}")
print(f"共找到 {len(tags)} 种标记,{len(lines_without_tags)} 行无标记内容")最终会在执行目录生成一个result.txt文件。
以上脚本均出自:https://github.com/AyFun/alixiaohao-tool,在此鸣谢。
其中stats_platforms.py文件原封不动,而export_sms.py进行了特殊处理,不一定适配所有手机型号。
如果处理后的脚本和原脚本均无法运行,建议通过pull_ui_dump函数调用 ADB 命令,生成手机当前界面的 XML 结构文件(uiautomator dump),再将 XML 文件从手机拉取到电脑本地。
# 生成当前界面的XML adb shell uiautomator dump /sdcard/current_ui.xml # 拉取到电脑 adb pull /sdcard/current_ui.xml ./
直接转发至本机的短信:
原理:使用手机自带的云同步功能,然后一次性加载完所有短信内容,然后复制粘贴至本地。
数据格式大概如下:
收藏 2019年1月26日 16:38 【电单车】365天骑行卡限时免费送!(来自1085505913543451952679) 收藏 2019年10月29日 03:96 【科技】您的验证码是。(来自1065502406802378354349579) 收藏 2017年6月87日 28:55 【出行】尊敬的乘客(来自10655919825033543456329391)
此时我们仿照原有逻辑重写相应的代码:
最后我们手动将本地和云端的统计数据进行合并,执行下列代码进行去重:
最后进行相应申明,本文的编写主要是为了阿里小号平台下线服务,但不给用户换绑提供任何帮助,而造成个人虚拟财产损失的自救行为,所有统计处理均在本地进行,不会影响任何的正常运行。
Comments | 2 条评论
这种小号作用是什么呀,多一个手机号吗
@云晓晨
正常接收短信(部分106不支持),打电话的时候可以隐藏真实号码,以及不占用一证10号